
In this article, we’ll explore the “L” — Load — phase of Change Data Capture (CDC), where we make captured changes available to downstream consumers in real-time. We’ll discuss two patterns for extracting and sharing change data, helping you understand which one suits your organization’s needs best.
Extracting and Sharing Change Data: Empowering Downstream Consumers Once all changes to the dataset are captured through CDC, the next step is to share this valuable information with downstream consumers. There are two main patterns for achieving this:
1. Extracting and Sharing Change Data via Shared Location: In this pattern, change data is extracted from the CDC system and made available through a shared location like S3, Kafka, or other message brokers. This centralized hub allows multiple downstream consumers simultaneous access to the data, facilitating real-time analytics and decision-making.
Example: A retail company captures changes to its inventory using CDC. The extracted change data is made available through Kafka, enabling the sales, marketing, and supply chain teams to access real-time inventory updates for efficient stock management.
2. Extracting and Loading Change Data Directly into Destination Systems: In this pattern, change data is extracted and directly loaded into the destination system. It’s a more straightforward approach, making it popular for smaller data streams or initial CDC deployments. It minimizes latency between data generation and its availability for analytical use.
Example: A social media platform captures changes to user interactions using CDC. The change data is loaded directly into the analytics database, enabling the data science team to perform real-time sentiment analysis for user engagement insights.
Selecting the Right Pattern: Tailoring to Your Needs Choosing the suitable pattern depends on various factors:
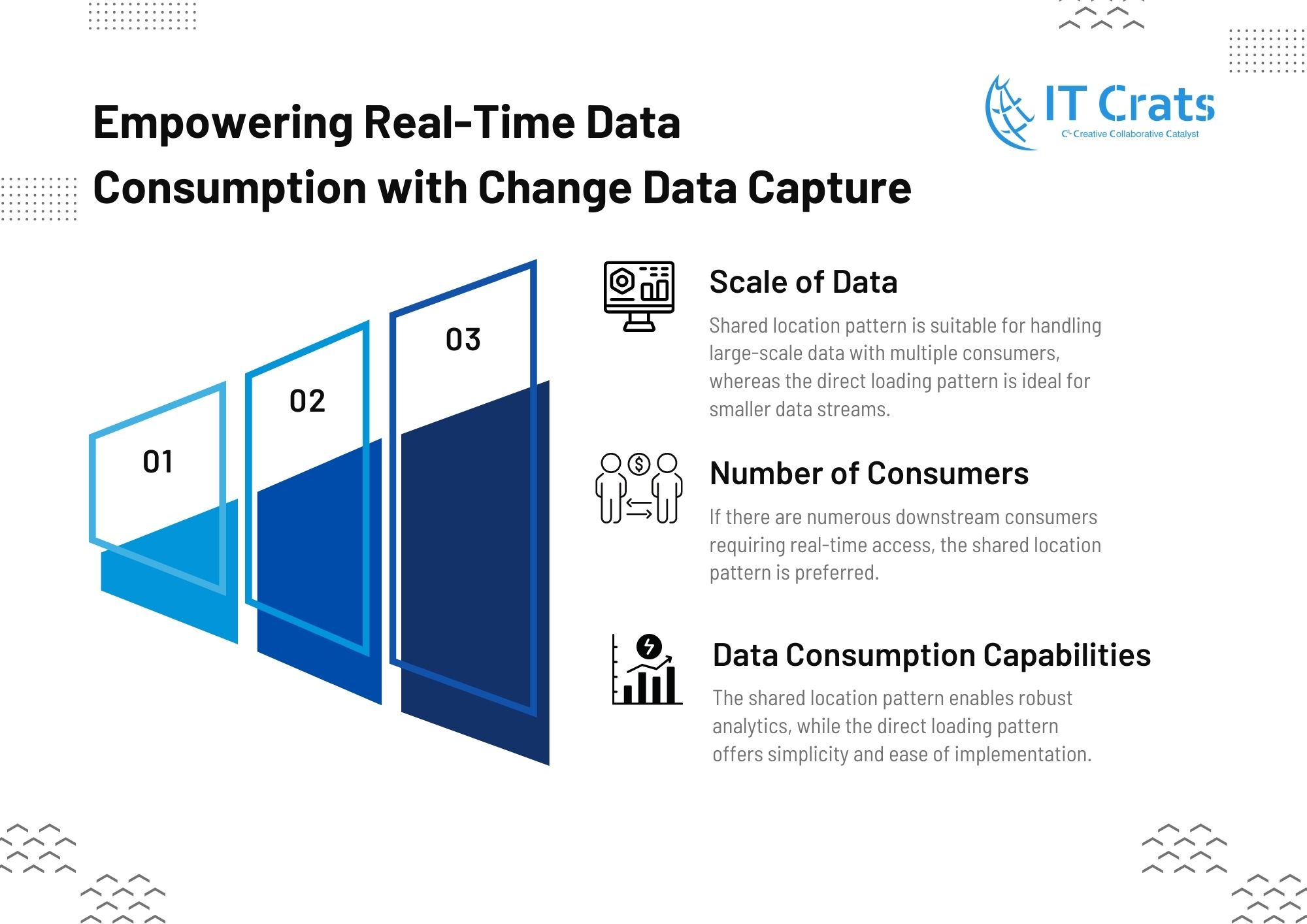
- Scale of Data: Shared location pattern is suitable for handling large-scale data with multiple consumers, whereas the direct loading pattern is ideal for smaller data streams.
- Number of Consumers: If there are numerous downstream consumers requiring real-time access, the shared location pattern is preferred.
- Data Consumption Capabilities: The shared location pattern enables robust analytics, while the direct loading pattern offers simplicity and ease of implementation.
Example: An e-commerce company implementing CDC needs to decide between the two patterns. Since they have multiple teams requiring real-time access to customer data for analytics, they choose the shared location pattern through Kafka.
Conclusion: The “L” — Load — phase of CDC empowers organizations with real-time data consumption, turning vision into reality. By selecting the right pattern, organizations unlock the full potential of CDC, enabling timely insights and data-driven decision-making.
Embrace the power of CDC to fuel your organization’s success! Whether you prioritize data sharing agility or simplicity in loading, CDC enhances data pipelines with unmatched efficiency.
Stay tuned for our upcoming articles, where we’ll delve deeper into implementing CDC with real-world examples and step-by-step guides!
Need help tailoring CDC to your organization’s needs? Drop us an email at hi@itcrats.com. We’re here to assist you on your data journey!








